

2024年11月5日下午,文研院第十七期邀访学者内部报告会(第十次)在静园二院111会议室举行。文研院邀访学者、明治大学法学院教授陶安(Arnd Helmut Hafner)作了题为“秦汉魏晋出土文书的文本编码研究”的报告,同期邀访学者梅建军、董玥、刘后滨、郭俊叶、赵伟、宋念申、韩炳华、鲁明军、黄冠云、李萌昀、张锦、吴功青、孟国栋、孟琢、焦姣、胡箫白、冯嘉荟,文研院副院长杨弘博等参加了报告会。黄冠云老师作为主持人介绍了陶安老师的研究领域和学术成果,杨弘博老师代表文研院向陶安老师颁发了邀访学者聘书。

▴
杨弘博副院长向陶安老师颁发邀访学者聘书
讲座伊始,陶安老师向大家介绍了本次报告会的选题缘起和基本内容。陶安老师指出,“文本编码”是他很感兴趣并且一直在探索的交叉学科领域,也是他计划在文研院驻访期间主要进行的工作。具体而言,“文本编码”作为“编码”的一种,不仅在技术上早已成熟,在近期也成为了日本学界的热门。而未来,文本编码还将借助电子化的载体与人工智能联系起来,成为一种重要的研究工具。就基本内容而言,他将从编码的概念讲起,介绍文本编码的简史,并重点为大家介绍一种特殊的编码体系——“TEI(Text Encoding Initiative文本编码倡议)-Guideline(指针)”,这是专门为人文科学的文本所开发的一种特殊编码方案。而他所做的工作则是将简帛学中内在的标记语言翻刻到TEI文本编码系统中,来看这将为简帛学的发展带来什么新的贡献。
首先,陶安老师介绍了编码的概念和发展历史。编码(Encoding)即使用规定的一组代码(code)来表示(en)某种信息。按照信息内容来分类,编码包括字符编码、文本编码、其他编码(图像、动画等)。而按照编码目的进行分类,则包括程序(procedural)指向/显示(presentational)指向和描述(descriptive)指向的编码。
字符最初以欧美语言为中心,ASCII(American Standard Code for Information Interchange)便是最早成立的一种字符编码。十几年后,东亚各国和地区也开始建立各自的编码体系,如JIS(日本产业标准字符集,1972年开始),KS(大韩民国产业标准字符集,1974年初次制定),GB(中华人民共和国国家标准、1981初次制定),BIG5(大五码/五大码,台湾财团法人信息产业策进会,1983年12月公开)等等。不过,这也带来了跨语言情境下编码无法统一的困境,于是便出现了我们今天常用的Unicode统一码。陶安老师强调:与文本编码比较的话,其实字符编码并不复杂,实质上就是一张一览表。ASCII由128/256(即extended ASCII)个字符构成,可以表示常见字母ABC和一些特殊的符号等等。而汉字的数量远不止此,所以统一码就有很多字符,但是从逻辑上来说,也不过是一个简单的一览表而已。
▴
Unicode字符集
中日韩统一表意文字扩充B区
但文本编码就没有这么简单了,它与字符编码在实际含义上存在差别。陶安老师以“My name is Hafner”这句话为例,对比了两种编码方式的差异。他指出,在字符编码中“a”用ASCII-Code(十六位)表示为“61”,ASCII-Code(二位)表示为“01100001”,由此,一句话可以用一串数字群来表达。不过,人虽然能够看懂这句话,但电脑仍然不知道这是什么。要让电脑明白此处的语法,我们还需要使用一种特殊的括号“< >”标注出主语、系词、谓语等,并告诉电脑登入的信息(如下图)。这种编好码的文本积累得多了,便可以用于语法统计,并收集一些统计数据(比如说哪些词常当做主语,哪些词平时不做主语等等)。

▴
用特殊括号“< >”标注出主语、系词、谓语等
那么,前述分类中所提到的“显示指向”与“描述指向”又有什么区别呢?陶安老师以另一句话“My name is Arnd”为例进行了阐发。他指出,有时我们会把个人名字使用斜体表示,如果采取刚刚那种标签来表示的话,可以写作“My name is Arnd”。这虽然也是一种编码,但电脑并不知道为什么此处是斜体,因为人们还会用斜体表示对某一部分的强调等。所以光用这一种编码,只能呈现平面上或打印时的状态,但电脑并不清楚具体意思到底是什么。而描述语言则用“”来表示人名这一固有名词,整句话便能写作“My name is Arnd”。并且,描述指向的编码在显示时可以选择斜体(Arnd)、下线(Arnd)、黑体(Arnd)等表述形式,运用到大型资料库中便可以一键转换相关标注的显示方式,进而大大提高工作效率。
其次,陶安老师向大家介绍了文本编码的历史。文本编码与字符编码几乎同时出现于上世纪六十年代。因为当人们在考虑电脑如何处理单个字的时候,也在同时考虑如何输入各种词汇,词数如何计算,以及如何自动编成索引等问题。上世纪六十年代,英国的Atlas Computer Laboratory(阿特拉斯电脑实验室)创建了一套词数计算及索引自动生成的编码方案。之后,不同人和机关开发了很多不同的编码体系,但问题在于不同体系之间互相不兼容,故仍然处于不同编码体系林立的时代。第一个改变这种状况的技术叫SGML(Standard Generalized Markup Language,1986年),即“标准化通用标记语言”。标记语言是在文本上打上不同标签的编码语言,但实际上SGML本非一个纯粹的标记语言,而是为了建立不同标记语言的标准化的规则体系。在这个规则体系的基础上,不同的标记语言之间可以实现相互翻译。
自上世纪八十年代SGML建立之后,它很快就孕育出许多有趣的产物,例如大家天天都在看的HTML(超文本标记语言,1989年)。HTML是一种连接文本与图像等信息的标记语言,它一开始以SGML作为基础。SGML为了建构不同的标记语言,往往会伴随一个描述标记语言词汇及语法的DTD(Document Type Definition,即文件类别定义)文件,所以使用时需要打开两个文件。但是我们今天常见的HTML大多只需要一个文件就可以,是因为它对SGML进行了简易化和标准化,故而任何电脑上都能一下就显示出网页来(CSS除外,本报告中不细谈)。不久之后,又出现了一种可扩展的标记语言,即XML(1996)。其中的“X”就是扩展性(Extensible)的意思。它将语言的既成符号缩小到仅由“<,>,&”,以及两种不同的引号(’,”)构成。故而,每一个使用者都可以自行定义标记语言,也能够实现不同标记语言间的兼容。例如,我们现在所熟知的PDF,Office里面的Doc,背后实际上都是XML。本报告所关注的TEI-Guideline(文本编码倡议指针)也是在采纳XML之后大大发展。为了使人文科学文本编码最佳化,它提供了540个标签,而且还允许使用者自行增减或变更标签。
然后,陶安老师重点向大家介绍了TEI文本编码体系的历史演变、基本结构和使用实例。TEI起初以欧美人文科学家和IT工作者为中心,起源于1987年在纽约会议发出的倡议。TEI-Guideline(文本编码指引)从P1到P5目前共经历了五代。TEI P1直至P3最初着重于具有机械可读性的文本(Guidelines for the Encoding and Interchange of Machine Readable Texts )。2002年TEI P4采用了刚才说到的XML这一几乎在我们所有的文件中都作为基础的形式之后,着重点略有变化,更强调保证所有文本能够被编码而交换的兼容性(Guidelines for Electronic Text Encoding and Interchange XML-compatible edition)。
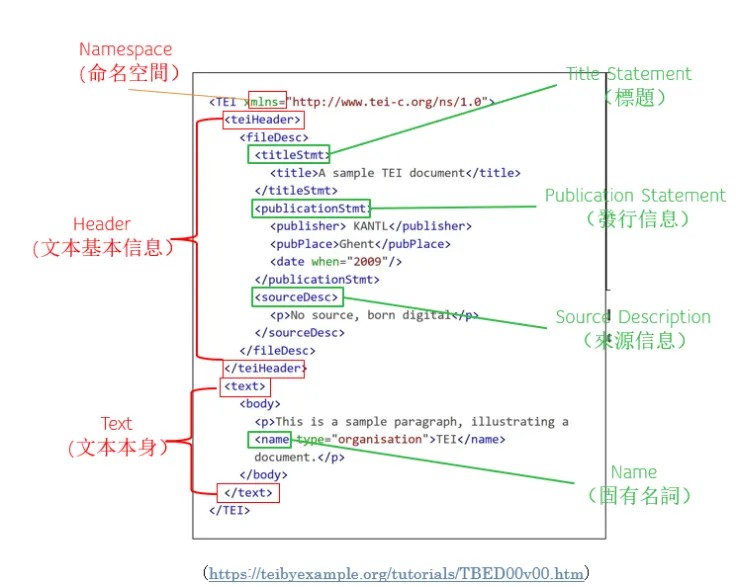
陶安老师还举出了一个简单的例子来说明其基本结构(如下图):
▴
TEI文本编码的基本结构
他指出,TEI编码体系主要可以分为三大块,第一块“mlns”是Namespace(命名空间),表示所使用的标记语言。其后放置的网址可以让电脑自动去找这一语言的相关标签。第二块Header(文本基本信息)包括标题“”、发行信息“”,以及来源信息“”等。真正的文本从第三块“Text”开始,此处只是一个简单的文本,但更长的文本在基本结构上也不会改变。
随后,陶安老师还介绍了TEI编码体系在欧美一些有趣的使用实例。例如,“The Walt Whitman Archive”中对六千多份书信的整理。网页中的“Source File”标注的是信息来源,后边跟着一个xml文件,这一网页的所有信息都在这样一个文档里。而有了这个文档,也可以自动生成网页,并将字和图像联系起来。

▴
“The Walt Whitman Archive”网站
https://whitmanarchive.org/item/loc.05437
另一个实例是“Perseus Digital Library”,它是希腊语、拉丁语等古文献资料的语料库。其中不仅包括原文、译文、注释,还有词汇、语法的解释等高级检索功能,而它们的背后都是TEI编码信息。故而,从最简单的一句话开始,只要调出足够多的内容,便可以建立起来一个相当复杂的语料库或资料库。
▴
“Perseus Digital Library”网站
https://www.perseus.tufts.edu/hopper/text?doc=Perseus:text:1999.02.0001
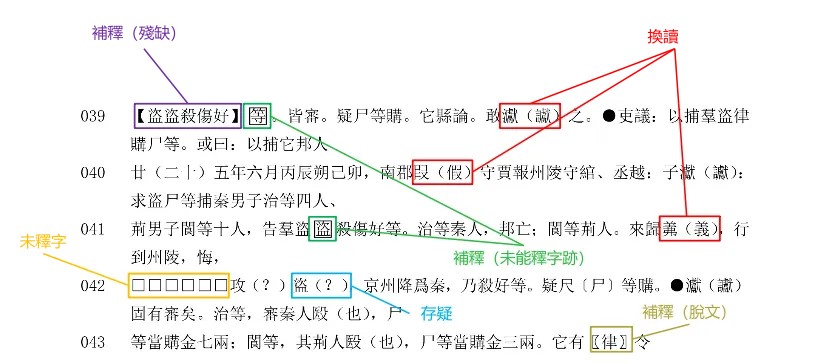
接着,陶安老师指出简帛学中也有内在的标记语言,并以他整理的岳麓秦简《为狱等状四种》的释文为例进行了阐释。他指出:除了汉字以外,我们可以看到释文里边有很多符号,包括小括号、中括号、大方块等等。这些符号都是标记语言,它们具备特定的意义,并非随意简化。譬如说小括号“()”表示的是换读。简单来说,当时人“奏讞”的“讞”习惯用三点水的“![]() ”,而传世文献则多用“言”字旁的这个字,所以我们就换上言字旁的“讞”。同理,“叚”具有借用或假如的意思,所以今天按照传世文献的用字习惯就换成了“假”字;而“羛”作为“義”的异体字,一般都用小括号表示。另外,其中还有许多补释。补释有不同的情况。比如说“盗”和“等”字,原简字迹不清,难以辨识,但根据前后文能够确定是这两个字,就在字外加方框表示。上述两字在简面上尚存痕迹,但如果开头部分的简牍已经残断,我们也可以猜出来是什么字,就用“【】”标示。而最后面的“它有律令”有很多词例,此简中却作“它有令”,所以我们就用“〖〗”补出脱文“律”字。再如,简42前面的“□”表示这里有字,但已经认不出来了。有时我们还用括注问号“(?)”表示对释读持存疑的态度。这些符号的含义在书前的“凡例”中都有介绍,许多人却未加注意。例如,陶安老师将“【】”作为补释残缺字的标记,但是很多人却为了方便将它跟“(?)”和“□”放到一块,在没有把握的地方全都打“【】”,这种做法就把标记语言的词义弄丢了。陶安老师强调,简面上是否留有字迹是非常关键的信息,标记符号可以帮助我们精确地描述简面上的信息,可谓十分重要。如果要将我们对简帛学所作的工作带入到AI时代,也必须将简帛学内在的标记语言翻刻到某一个电子化的编码体系中去。
”,而传世文献则多用“言”字旁的这个字,所以我们就换上言字旁的“讞”。同理,“叚”具有借用或假如的意思,所以今天按照传世文献的用字习惯就换成了“假”字;而“羛”作为“義”的异体字,一般都用小括号表示。另外,其中还有许多补释。补释有不同的情况。比如说“盗”和“等”字,原简字迹不清,难以辨识,但根据前后文能够确定是这两个字,就在字外加方框表示。上述两字在简面上尚存痕迹,但如果开头部分的简牍已经残断,我们也可以猜出来是什么字,就用“【】”标示。而最后面的“它有律令”有很多词例,此简中却作“它有令”,所以我们就用“〖〗”补出脱文“律”字。再如,简42前面的“□”表示这里有字,但已经认不出来了。有时我们还用括注问号“(?)”表示对释读持存疑的态度。这些符号的含义在书前的“凡例”中都有介绍,许多人却未加注意。例如,陶安老师将“【】”作为补释残缺字的标记,但是很多人却为了方便将它跟“(?)”和“□”放到一块,在没有把握的地方全都打“【】”,这种做法就把标记语言的词义弄丢了。陶安老师强调,简面上是否留有字迹是非常关键的信息,标记符号可以帮助我们精确地描述简面上的信息,可谓十分重要。如果要将我们对简帛学所作的工作带入到AI时代,也必须将简帛学内在的标记语言翻刻到某一个电子化的编码体系中去。

▴
《岳麓秦簡〈为狱等状四种〉释文注释》(修订本)
[德]陶安
上海古籍出版社,2021年
▴
陶安老师岳麓秦简《为狱等状四种》释文中不同符号的含义
下一步,陶安老师详细介绍了他运用TEI来表示简帛学中标记语言的实例。比如说要换读某个字,在TEI中可以使用三个标签“<orig>(original原文),<reg>(regularization正则化),<choice>(选择)”来表示。换读有两种格式,其一为“A(B)式”,以“士五(伍)轎”为例,编码时先用一个表示对两种信息的选择,“五”作为原文用<orig>表示,而“伍”则用“<reg>”表示我们现在使用的规范字形。由此,我们在一个大型语料库中便能列出类似于通假字典的换读表。其二为“A(B-C)式”,换读的情况稍微复杂一些,以“而言(音-意)毋(無)坐殹(也)”为例,“言”读为“音”,又读为“意”。许多搞简牍的人常常不考虑这中间为什么会有一个横杠,“音”“意”和“言”又到底是什么关系?而文本编码将使我们有机会考虑这个问题。人们习惯把古人所用的“音”字理解为传世文献中的“意”字,但是把“言”直接读为“意”并不常见,所以“<choice>”在这里就要出现两次,大的选择是原文“言”和正则化的“意”,然后原文(<orig>)里面还有一个“<choice>”,其下再用“<sic>”表示真正的原文如此。这枚简上用的虽然是“言”字,但是按照那个时代的正则化标准来看的话,古人也常用“音”字。所以我们经过两次转换,由“言”先改为“音”又改成后代习用的“意”,表示“以为”的意思。

▴
陶安老师用TEI表示简帛学中标记语言的实例
错字在简牍释文中用“〔〕”表示,同样可以用上述“<sic>”(原文如此)的标签,后面加一个“<corr>”(correction)的标签加以订正。错字也有两种情况:简单情况即“A〔B〕”式,以“苛視不![]() 〔狀〕者”为例,很容易标注。复杂的情况“A〔B‐C〕”式,其中也有一个横杠。以“
〔狀〕者”为例,很容易标注。复杂的情况“A〔B‐C〕”式,其中也有一个横杠。以“![]() 〔就-僦〕日未盡”为例,需要先将错字“
〔就-僦〕日未盡”为例,需要先将错字“![]() ”改为当时的常用字“就”,然后按照后代的规范,用“僦”来表示雇佣关系。所以编码时又出现了两个“<choice>”,并按照当时的标准加以“订正”(<corr>),再“正则化”(<reg>)为后代的常用字。
”改为当时的常用字“就”,然后按照后代的规范,用“僦”来表示雇佣关系。所以编码时又出现了两个“<choice>”,并按照当时的标准加以“订正”(<corr>),再“正则化”(<reg>)为后代的常用字。

▴
TEI标示简牍中的错字
未释字在简牍释文中有“□”和“……”两种标记。在TEI中可以用到“<gap>(缺口/脱漏), @reason(理由), “illegibility”(模糊难辨), @quantity(数量), @unit(单位)”等标签。其中“@quantity”是对属性的描写,可以进行更详细的描述。具体而言,第一种标记以“□□□盜,非吏所興”为例,可以编码为“盜,非吏所興”。其中<gap reason="illegibility"表示简文残缺的原因是看不清,于是就框进去了三个字(quantity="3")。不过这样的话三个方块就变成了一个标签,会被电脑视为一个字符串,自动化处理中失去字数与编码元素的对应关系,将会对后续不同文本之间的比较产生影响。为此,不妨用三个标签,每个字都按照方块字的逻辑来处理,写作:
<gap reason="illegibility"quantity="1"unit="char"/><gap reason="illegibility" quantity="1" unit="char"/><gap reason="illegibility" quantity="1"
unit="char"/>“盜,非吏所興”
第二种情况,即在无法释读和辨认所缺字数时,我们可以使用“@extent”这个表示范围的标签,并标注“unknown quantity of characters”。以“馮將軍毋擇……食……”为例,其编码作:
“<gap reason="illegibility" extent="unknown quantity of characters"/>”
存疑字在简牍释文中往往使用“(?)”来表示,TEI中往往使用“<certainty>(确实性,可信度), @locus(位置), @degree(程度)”这几个标签来表示,但是需要注意到标注存疑字可能会影响到原简字数与编码元素数量之间的对应关系。为此,陶安老师指出,我们可以将存疑字本身改为一个标签,在编码的开头给他们一个ID,使用“<g>(glyph符号、字符)”这一标签表示。例如,为狱等状中大概有830个字符,在陶安转换方案中“盜”的ID为29,于是“盜(?)”便可以改写为<g ref =“#29“ cert=”low”>,其中还用到了“cert”(certainty确实性,可信度)来显示可信度的高低。
有趣的是,TEI看似与简帛学毫无关系,但是从中都能找到与简帛学对应的标签。在补释的情况下,我们依然可以使用“<supplied>(被补充), @reason(理由), “illegibility”(模糊难辨)”这几个标签。例如,“敢![]() (讞)之”中的“敢”已经模糊不清,但是根据语境可以确定“
(讞)之”中的“敢”已经模糊不清,但是根据语境可以确定“![]() ”字前一定是它,那么就可以给它加一个“”,(TEI中写作<supplied reason= “illegibility”>敢
”字前一定是它,那么就可以给它加一个“”,(TEI中写作<supplied reason= “illegibility”>敢![]() </supplied>(讞)之)。若有两个连续的未释字,可以把二者放到同一个标签中,但为了保持字数与元素数量的对应关系,仍然应当分别括注。这种方法也适用于原简在抄写时有所遗漏或残断的情况,只需要将理由(@reason)改成遗漏(“omission”)或损伤(“damage”)便可。例如,“【得、】文、芻、慶、綰【等曰:與】反寇戰”中的“<supplied reason= “damage”>得</supplied>”便可以用“得”表示。有时简牍中还会出现“【□□□】”和“【……】”,同样可以使用上面提到的标签来表示。
</supplied>(讞)之)。若有两个连续的未释字,可以把二者放到同一个标签中,但为了保持字数与元素数量的对应关系,仍然应当分别括注。这种方法也适用于原简在抄写时有所遗漏或残断的情况,只需要将理由(@reason)改成遗漏(“omission”)或损伤(“damage”)便可。例如,“【得、】文、芻、慶、綰【等曰:與】反寇戰”中的“<supplied reason= “damage”>得</supplied>”便可以用“得”表示。有时简牍中还会出现“【□□□】”和“【……】”,同样可以使用上面提到的标签来表示。
最难表示的是重文符号,TEI中有对应的标签:“<abbr>(abbreviation省略),<am>(abbreviation marker,表示省略的标记,即此处的重文符号),<expan>(expansion,扩展), <ex>(editorial expansion,编者所加)”,可是具体处理起来却并不容易。考虑到简帛学中的重文符号有一定的规律,可以分为三类,第一类“A=(AB/BA)”,例如“粟=”指的是“粟米”,而“夫=”则指代“大夫”。由于文字排布的前后顺序并不固定,在自动化处理中就会成为相当麻烦的问题。第二类“A=B=(AB+标点+AB)”,例如“爲=秦=”应当写作“爲秦。爲秦”,中间会出现标点符号。第三类是“A = (A-B+标点+A-B)”,例如“勿環=(環-還!環-還)之”,里面同时出现了换读和标点。为此,陶安老师的解决办法是:首先使用“<choice>”标签表示选择,然后按照原文中的省略形式加上标签,“扩展”(<expan>)时则在后面所加字之处附上“<ex>”标签。而如果中间还有横杠的话,就只需要在省略的标记形式(<abbr>)中再加上换读即可。

▴
用TEI标示重文符号的实例
目前,书写XML形式的文本需要专门的编辑器,很多搞TEI的人正在手动编辑这些文本。但是,下一步,如果还想加入词汇、语法等标签的话,工作量不免浩繁,所以简帛学的电子化还需要与人工智能结合起来。陶安老师指出,目前OCR和HTR(手写文本识别)的技术已经能够实现文字的批量识别。下一步,我们可以在充分校正文本的基础上,利用Python设计一个可以将它们批量改为XML的自动化程序。再往下,这种XML文件又可以通过XSLT技术转换成PDF或TXT格式的文本。在上述流程完成之后,未来,我们借助AI还可以进行版本的自动化比较、索引的自动化编辑等一系列工作。
最后,陶安老师总结道:“我们早晚将进入人工智能的时代,如果不想被人工智能牵着鼻子走,那自己就先得懂得这个技术,然后看看怎么去用它,别让它来用我们。”
讨论环节
在讨论环节,梅建军老师指出陶安老师“走在了时代前列,走在了AI前列”,并对他做这件难度如此之大的事情的初心表示了好奇。对此,陶安老师回忆了自己带领读书班为里耶秦简做译注的经历。当时,为了提高注释的效率和便于记忆,他萌生了想要借助HTML形式建立一个小资料库的想法。不过,这一资料库虽然用起来很方便,但维护起来却很费事,也难以加入读书班的成果。后来他得知有TEI这样一个较为完善的文本编码体系,相关技术也有公开的材料供人学习,于是就开始了探索。后来,考虑到手动编码比较繁琐,所以他又去学了一点Python。讲到这里,陶安老师还顺带介绍了自己建立起来的网站——“资料库实验室”,上面也公开发布了他自2021年来持续探索的心得。

▴
“资料库实验室”网站
http://www.aa.tufs.ac.jp/users/Ejina/DBexperimental.html#07
张锦老师指出这种数据库建立的过程中还有一个非常难的环节,即需要人工来核对底层文献,以确保其精准性。孟琢老师也以北师大开发的“数字化说文解字”系统为例,强调一个干净的底本背后往往离不开学者们付出的艰辛努力。对此,陶安老师向大家分享了自己在校正文本过程中积累的相关经验。此后,学者们还围绕“文书”与“文献”在电子化过程中的差异、简牍数据库为学术研究带来的新期待等议题展开了讨论。本次报告会在热烈的氛围中结束。
